

Zmierzymy się dziś z dość trudnym problemem weryfikacji wydajności kodu. Już wkrótce przekonasz się, jak wiele na pozór prostych rzeczy nie zawsze działa tak, jak można by się tego na początku spodziewać. Ten tekst będzie zawierał listę zagadnień dotyczących tego, co potencjalnie może pójść nie tak podczas mierzenia czasu wykonania naszej aplikacji. Wprowadzimy również pojęcie benchmarku oraz zapoznamy się z biblioteką Java Microbenchmark Harness, przy pomocy której w wygodny sposób można testować nasz kod i jednocześnie nie osiwieć.
Zaprezentowane przykłady odwołują się do kodu w Javie, jednak część wniosków jest bardziej uniwersalna i niezależna od wykorzystywanego języka programowania.
Naiwne podejście do mierzenia czasu
Jak w większości języków programowania w Javie również istnieje opcja pobrania aktualnego czasu. Skoro mamy taką możliwość, to może wystarczy sprawdzić czas przed rozpoczęciem obliczeń, a potem po ich zakończeniu i obliczyć różnicę?
Prawda, że proste?
long startTime = System.currentTimeMillis(); work(); System.out.println(startTime - System.currentTimeMillis());
Ale skoro to takie proste i kod wydaje się działać, to o co to całe zamieszanie!?
Problemy z mierzeniem wydajności kodu Javy – czyli co właściwie może pójść nie tak?
No właśnie. Niestety to zagadnienie nie jest tak proste, jak można by się tego spodziewać. Prześledźmy teraz listę najpopularniejszych problemów, na jakie możemy natrafić podczas mierzenia czasu wykonania kodu. Zapewniam Cię jednak, że są to tylko najczęstsze problemy i zdecydowanie nie wyczerpują one tematu.
Pułapka #1. Ziarnistość pomiaru czasu – System.currentTimeMillis
Metoda System.currentTimeMillis zwraca liczbę milisekund, które minęły od 1 stycznia 1970, od godziny 00:00. Wartość początkowa lokalnego czasu jest uzależniona od zegara systemowego, także może zostać zmieniona przez użytkownika komputera.
Kolejnym problemem jest maksymalna dokładność, jaką możemy uzyskać przez ziarnistość pomiaru czasu. Ziarnistość czasu jest powiązana z częstotliwością aktualizacji źródła naszego czasu. Przykładowo, jeżeli liczymy czas między kolejnymi przejazdami samochodów przez skrzyżowanie i nasz stoper pokazuje wynik z dokładnością co do jednej minuty, to nie osiągniemy większej dokładności niż właśnie jedna minuta.
Podobnie jest z komputerami. System operacyjny regularnie „sprawdza” aktualny czas i udostępnia tę informację np. naszej aplikacji. Jeżeli między jedną a drugą aktualizacją czasu zdążymy odpytać z naszego kodu o ten czas 2 razy, to otrzymamy dokładnie ten sam rezultat. Zafałszuje to oczywiście wyniki naszych testów.
Możemy o tym przeczytać między innymi w dokumentacji metody: currentTimeMillis.
/** * Returns the current time in milliseconds. Note that * while the unit of time of the return value is a millisecond, * the granularity of the value depends on the underlying * operating system and may be larger. For example, many * operating systems measure time in units of tens of * milliseconds. ... */ public static native long currentTimeMillis();
Pułapka #2. Pomiar wpływa na wynik pomiaru – System.nanoTime
Środowisko Javy udostępnia nam jeszcze jedną metodę do mierzenia czasu: System.nanoTime().
Sądząc po nazwie, metoda oferuje dokładność aż do nanosekundy, co wydaje się bardzo obiecujące, dlatego przyjrzyjmy jej się bliżej.
Z dokumentacji metody wynika, że podaje ona różnicę czasu między pewnym punktem w czasie a chwilą obecną. Ten punkt jest stały w obrębie jednej maszyny wirtualnej, może być jednak inny na różnych maszynach. W efekcie tego można tę funkcję wykorzystać tylko do pomiaru różnicy czasu między jednym a drugim odczytem – co w naszym przypadku jest w zupełności wystarczające.
Czytając jednak dalej dokumentację, znajdziemy podobne ostrzeżenie o ziarnistości czasu jak w przypadku poprzedniej metody. Niestety wynik dalej będzie bardzo mocno uzależniony od systemu operacyjnego, na którym przeprowadzamy testy.
/** * Returns the current value of the running Java Virtual Machine's * high-resolution time source, in nanoseconds. * *This method can only be used to measure elapsed time and is * not related to any other notion of system or wall-clock time. * The value returned represents nanoseconds since some fixed but * arbitrary origin time (perhaps in the future, so values * may be negative). The same origin is used by all invocations of * this method in an instance of a Java virtual machine; other * virtual machine instances are likely to use a different origin. * *
This method provides nanosecond precision, but not necessarily * nanosecond resolution (that is, how frequently the value changes) * - no guarantees are made except that the resolution is at least as * good as that of {@link #currentTimeMillis()}. ... */ public static native long nanoTime();
Dodatkowo wywołanie metody nanoTime obarczone jest większym narzutem na wydajność niż – currentTimeMillis. Spowodowane jest to inną implementacją tych dwóch metod. Dlatego etap poświęcony na pobranie informacji o czasie wpłynie na ostateczny wynik pomiaru.
System.currentTimeMillis vs System.nanoTime
Java oferuje nam dwie metody do pomiaru czasu: System.currentTimeMillis oraz System.nanoTime. Jednak z której powinniśmy skorzystać w naszym konkretnym przypadku?
public static long currentTimeMillis()
- Metoda jest thread safe, czyli bezpiecznie możemy ją wykorzystywać w środowisku wielowątkowym.
- Może być wykorzystywana do sprawdzenia aktualnego czasu, ponieważ zawsze zwraca czas, jaki minął od stałego punktu w czasie: 1 stycznia 1970.
- Ma mniejszą precyzję pomiaru.
- Jest relatywnie szybsza, ponieważ jej implementacja opiera się tylko na odczycie przygotowanej wcześniej zmiennej.
- Może zwracać błędne wyniki ze względu na możliwość zmiany czasu systemowego przez użytkownika.
public static long nanoTime()
- Metoda nie jest thread safe.
- Nie może być wykorzystywana do sprawdzenia aktualnego czasu, ponieważ zwraca czas, jaki minął od nieustalonego punktu w czasie.
- Ma większą precyzję pomiaru.
- Jest relatywnie wolniejsza, ponieważ jej implementacja oparta jest na wyliczeniu czasu.
Podsumowując wnioski, metoda nanoTime powinna być wykorzystywana wszędzie tam, gdzie potrzebujemy większej precyzji pomiarów. Jednak jeżeli nie jest to dla nas aż tak kluczowe i precyzja dostarczona przez currentTimeMillis jest dla nas wystarczająca, powinniśmy korzystać z tej metody, ponieważ jest szybsza i może być wykorzystywana w środowisku wielowątkowym.
Pułapka #3. Izolacja pomiarów – co ja właściwie mierzę?
Przed rozpoczęciem pomiarów upewnij się, że mierzysz dokładnie to, co chcesz mierzyć. Wbrew pozorom wcale nie jest to takie oczywiste. Kod, który chcesz poddać testom, powinien być możliwie jak najprostszy i jak najkrótszy. Jeżeli natomiast logika składa się z kilku niezależnych fragmentów, to podziel ją i osobno poddaj testom. Dzięki temu będziesz miał pewność, że wyniki nie są zakłamane przez kod, który niejako był przy okazji testowany.
Z izolowaniem benchmarków należy jednak również uważać. Izolacja pomiaru w praktyce oznacza utworzenie jakiegoś z góry określonego środowiska dla naszego testu. W praktyce może się okazać, że produkcyjnie kod będzie działał w całkowicie innym środowisku.
Pułapka #4. Wpływ środowiska zewnętrznego – czyli różnica między czasem, który minął, a czasem wykonania
Nie zapomnij też o odpowiednim przygotowaniu maszyny, na której przeprowadzasz testy. Jeżeli na komputerze będą uruchomione inne aplikacje, które spowalniają działanie całego systemu, z pewnością odbije się to też na wynikach. W efekcie zmierzysz czas, który upłynął od rozpoczęcia do zakończenia testów, a nie rzeczywisty czas wykonywania operacji.
Dodatkowo systemy operacyjne uruchamiają niektóre zadania cyklicznie, co pewien czas. Może się zdarzyć, że podczas swoich testów trafisz na takie zadanie i kod będzie działał wolniej, niż moglibyśmy się tego spodziewać. Żeby uchronić się od tego typu problemów, najlepiej powtórzyć swoje pomiary kilkukrotnie i rozciągnąć je w czasie, tak by zniwelować ewentualne wahania wydajności.
Pułapka #5. Różnice w konfiguracji hardware oraz software
To, jaki komputer wykorzystasz do testów (czyli RAM, CPU itp.), ma oczywiście ogromne znaczenie dla osiąganych rezultatów. Dodatkowo system operacyjny, implementacja maszyny wirtualnej Javy czy nawet wybór wersji 32- lub 64-bitowej wpływają na wydajność aplikacji. Dlatego, przeprowadzając testy, trzeba podać, jakie środowisko zostało wykorzystane do ich przeprowadzenia.
Ciekawostką jest to, że niektóre optymalizacje dostępne są tylko na konkretne konfiguracje, a co ważniejsze – niektóre błędy oprogramowania występują też tylko na konkretnych konfiguracjach.
Pułapka #6. Optymalizacja kompilatora
Kompilatory w dzisiejszych czasach są już bardzo sprytne i potrafią doprowadzić do sytuacji, że wynikowy bytecode działa wydajniej, niż wynikałoby to ze struktury samego kodu źródłowego. Przykładowo, jeżeli podczas kompilacji uznają, że dany fragment kodu da się zapisać w inny, wydajniejszy sposób, to go zwyczajnie zmienią.
Brzmi groźnie?
Ponieważ takie optymalizacje nie wpływają na działanie aplikacji pod względem funkcjonalnym, a jedynie usprawniają niektóre fragmenty, zazwyczaj jest to bardzo pożądane działanie. Jednak z punktu widzenia przeprowadzanych testów wydajności może to znacząco wpłynąć na nasze wyniki.
Poniżej kilka najczęstszych optymalizacji, na które możesz natrafić.
Optymalizacje pętli
Pętle są bardzo problematyczne dla dzisiejszych procesorów, ponieważ do ich wykonania konieczne są operacje skoków. Procesor nie może wtedy pobrać i wykonać kilku kolejnych operacji w jednym cyklu, co znacząco wpływa na zmniejszenie wydajności.
Dlatego powstało wiele sposobów na ich optymalizację podczas kompilacji.
Rozwijanie pętli (loop unrolling)
To sztuczka polegająca na redukcji ilości iteracji w pętli przez kilkukrotne powtórzenie jej zawartości w ciele pętli.
// PRZED optymalizacją
for(int i=0; i<10; i++){
work();
}
// PO
for(int i=0; i<5; i++){
work();
i++;
work();
}
Powyższy przykład przedstawia, jak mogłaby być zredukowana ilość powtórzeń pętli aż o połowę.
Łączenie pętli (loop fusion)
Jeżeli sąsiednie pętle mają te same warunki iterowania, to mogą zostać połączone w jedną pętlę.
int[] array = new int[10];
// PRZED
for(int i=0; i<10; i++){
array[i] = 1;
}
for(int i=0; i<10; i++){
array[i] = 2;
}
// PO
for(int i=0; i<10; i++){
array[i] = 1;
array[i] = 2;
}
Spłaszczenie (loop collapsing)
Zastąpienie zagnieżdżonych pętli jedną bardziej rozbudowaną pętlą.
Eliminacja martwego kodu (dead code elimination)
Jeżeli kompilator wykryje, że fragment Twojego kodu nie ma wpływu na działanie aplikacji, np. po przeprowadzeniu obliczeń ich wynik nie jest nigdzie wykorzystywany, może nawet podjąć decyzję, żeby zignorować te obliczenia i zrezygnować z wykonywania tego fragmentu aplikacji.
for (int i = 0; i < 100; i++) {
long result = work();
}
Wyliczanie wartości stałych (constant folding)
Wyliczenie wartości powtarzających się wyrażeń może zostać zastąpione ich wynikiem, tak by nie trzeba było ich liczyć za każdym razem.
private static int work() {
return 1 + 2;
}
Pułapka #7. Cache współczesnych procesorów – fałszywe udostępnienie (false sharing)
Problem występuje w środowisku wielowątkowym, gdy dwa wątki wpływają nieumyślnie na swoją wydajność, modyfikując niezależne zmienne, które współdzielą ten sam fragment cache.
Pierwszy wątek modyfikuje jedną zmienną, powodując przeładowanie całego fragmentu cache, natomiast drugi wątek zmuszony jest do dociągnięcia swojej zmiennej z pamięci, mimo że jego zmienna nie została zmodyfikowana. Więcej na ten temat przeczytasz pod tym linkiem.
Pułapka #8. Zimna Java – WARM-UP
Pierwsze uruchomienie kodu na maszynie wirtualnej jest zazwyczaj dużo wolniejsze niż kolejne. Dzieje się tak, ponieważ Java jeszcze się odpowiednio nie rozgrzała. Podobnie jak biegacz przed ważnym startem zaczyna od rozgrzewki, tak i Ty nie powinieneś przeprowadzać prób wydajnościowych na „zimnej” Javie.
Wynika to z faktu, że za pierwszym razem dociągane są wszystkie niezbędne konfiguracje, ładowane – wykorzystywane klasy oraz przebudowywane – różnego rodzaju cache. Późniejsze wywołania mogą już spokojnie korzystać z przygotowanych zasobów i będą działały szybciej o czas potrzebny na ich przygotowanie.
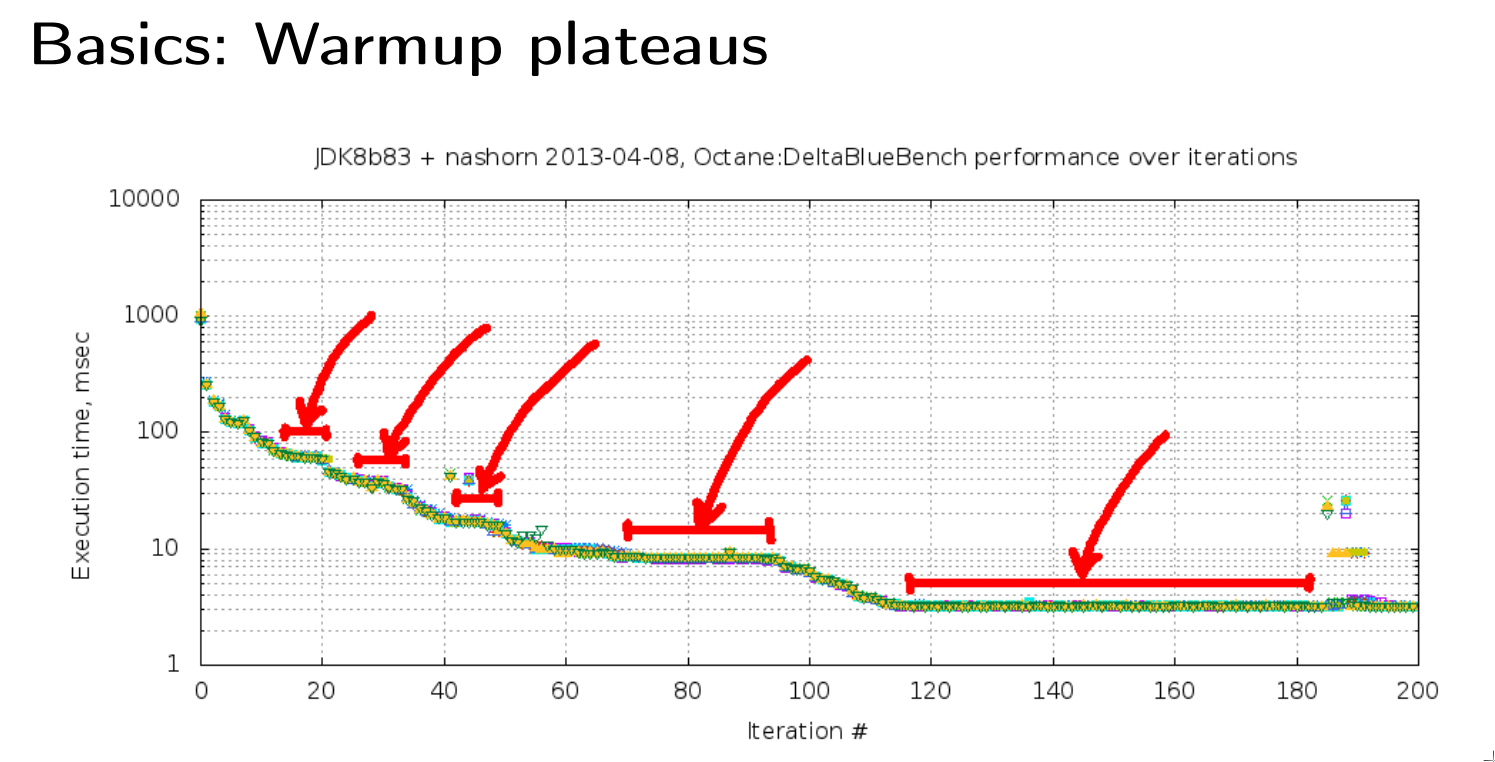
Pułapka #9. Zarządzanie energią
Coraz popularniejsze stają się systemy zarządzania zasilaniem w komputerach, których celem jest odpowiednie zbalansowanie zużywanej energii oraz wydajności. Do najpopularniejszych systemów tego typu można zaliczyć TurboBoost, Cool&Quiet, cpufreq oraz SpeedStep.
Upewnij się, czy Twój komputer nie działa na pół gwizdka, np. z powodu odłączonego zasilacza, lub czy podczas testów i zwiększonego obciążenia nie uruchamiają się nagle dodatkowe rdzenie procesora.
Co to jest benchmark?
Skoro wiemy już, co może pójść nie tak, zastanówmy się, jakie mamy narzędzia i możliwości, by nasze pomiary były bardziej miarodajne. Zacznijmy od wprowadzenia pojęcia benchmarku, czyli testu wzorcowego, który jest nierozerwalnie związany z mierzeniem wydajności.
W ogólności benchmark (test wzorcowy) to test weryfikujący wydajność systemu komputerowego, sprzętu lub oprogramowania. Wyniki analizy mają na celu porównanie ze sobą różnych procesów lub próbę ich optymalizacji.
W praktyce benchmarki często wykorzystywane są do analizowania różnych rozwiązań. Poddając je dokładnie tym samym testom, można łatwo stwierdzić, które rozwiązanie lepiej radzi sobie w modelowych warunkach.
Jak benchmark może nam pomóc, czyli po co to robić?
Osobiście bardzo lubię benchmarki i wszelkiego innego rodzaju izolowane testy, dlatego staram się je wykorzystywać w swojej codziennej pracy. Pokażę Ci teraz, co między innymi dzięki takiemu podejściu możemy osiągnąć.
Zaleta #1. Eksperymentowanie z nowymi rozwiązaniami
Zamiast budować wielkie rozwiązanie i opierać jego sukces na trudnych do zweryfikowania założeniach, dużo bezpieczniej jest zacząć od prostego prototypu rozwiązania i poddać go testom. Jeżeli podczas testu wyjdzie, że dane rozwiązanie nie jest wystarczające, oszczędzi nam to wiele zbędnej pracy.
Podobnie sprawa wygląda w drugą stronę. Może się okazać, że rozwiązanie, które na pierwszy rzut oka wydaje się niewystarczające, a którego implementacja jest znacząco prostsza, w testach wypadnie na tyle dobrze, że zdecydujemy się z niego skorzystać.
Zaleta #2. Porównanie wydajności alternatywnych rozwiązań
Podobnie jak w poprzednim przykładzie. Tu jednak skupiamy się na wyborze z kilku różnych rozwiązań. O ile przygotowanie rozwiązania w dwóch różnych wersjach czasem jeszcze jest do zrobienia, to jednak jeżeli rozważamy pięć lub więcej alternatywnych bibliotek, protokołów itp., to przygotowanie tylu pełnych wersji może być już bardzo kosztowne i czasochłonne.
Zaleta #3. Tuning
Dobrze przygotowany benchmark powinien pozwalać nam również na dokręcanie przysłowiowej śruby. Lekka zmiana konfiguracji i mamy możliwość odpalenia wszystkich testów i sprawdzenia, która konfiguracja sprawdza się najlepiej.
Jak można zdefiniować wydajność aplikacji?
Zanim przejdziemy do konkretnych pomiarów, trzeba się najpierw zastanowić, co to dokładnie znaczy, że dany kod działa wydajnie.
Wydajnie, czyli jak?
Może zużywa mało pamięci? A może działa szybko? Szybko, czyli jak? A jeżeli szybko, to czy za każdym razem tak samo szybko? Może średni czas wykonania jest zadowalający, ale zdarzają się wykonania, które zajmują dużo więcej czasu niż przeciętnie.
Możliwości jest naprawdę wiele, dlatego zanim zaczniemy coś mierzyć i dokonywać optymalizacji, zawsze trzeba się zastanowić, co tak naprawdę jest naszym celem. Musisz jednak pogodzić się z faktem, że nie ma czegoś takiego jak idealnie wydajna aplikacja czy funkcja. Zazwyczaj jest coś za coś, np. kosztem większego zużycia pamięci uzyskamy krótszy czas przetwarzania danych itp. Pytanie, co w danym przypadku jest dla Ciebie ważniejsze.
Wydajność #1. Przepustowość (throughput)
Przepustowość, czyli ilość operacji w danej jednostce czasu, np. ile razy dana metoda wykona się przez jedną sekundę.
Wydajność #2. Średni czas odpowiedzi (average time)
Średni czas wykonania wszystkich prób. Ze średnią trzeba jednak uważać, bo jej interpretacja w skrajnych wypadkach może prowadzić do błędnych wniosków. Niektóre sytuacje są na tyle kuriozalne, że doprowadziły do powstania licznych dowcipów, np.
Ja i mój pies średnio mamy trzy nogi.
Jeśli mój sąsiad codziennie bije swoją żonę, ja zaś nie biję jej nigdy, to średnio obaj bijemy je co drugi dzień.
Nie znaczy to jednak, że ta informacja jest bezużyteczna. Trzeba jedynie mieć na uwadze, jak jest wyliczana.
Wydajność #3. Rozkład statystyk
Rozkład statystyk wprowadza trochę więcej informacji. Zazwyczaj wyliczamy średni, minimalny i maksymalny czas wykonania. Takie przedstawienie danych również może nie być idealne, dlatego czasem odcina się z pomiarów skrajne wartości – czyli przebiegi najwolniejsze i najszybsze.
Wydajność #4. Histogram
Pełniejsze informacje otrzymamy dzięki wykorzystaniu histogramów. Żeby przedstawić dane w takiej formie, musimy podzielić zakres wartości na podzbiory. Przykładowo, jeżeli wiemy, że nasza metoda zazwyczaj wykonuje się w czasie do 10 ms, to możemy podzielić ten czas na 10 zbiorów, co 1 milisekundę. Do ostatniego zbioru wrzucimy wszystkie wartości skrajne, czyli większe niż 9. Teraz, jeżeli przyjdzie jakiś pomiar, to sprawdzamy, w którym zbiorze się mieści i zwiększamy licznik tego zbioru.
Poniżej przykładowy histogram. Zgodnie z naszymi założeniami mieliśmy trzy pomiary w czasie poniżej 1 ms, jeden w czasie od 1 do 2 ms itp.
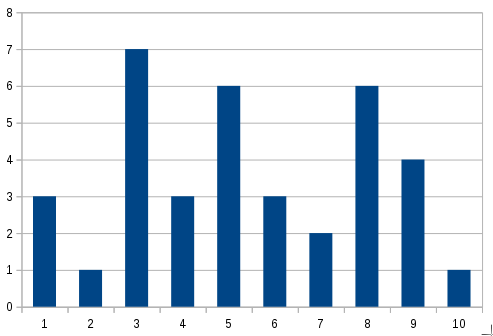
Jednostki czasu
Jeżeli jesteśmy już przy mierzeniu czasu, to tak dla formalności przypomnę najpopularniejsze jednostki, którymi się posługujemy. Niby nie ma w tym nic skomplikowanego, ale sam czasem mam pewne wątpliwości, gdy operuję na bardzo małych albo bardzo dużych liczbach.
W Polsce obowiązuje nas Układ SI, czyli Międzynarodowy Układ Jednostek Miar, który definiuje sekundę jako jednostkę podstawową oraz pozostałe wykorzystywane tu miary jako jednostki pochodne.
Sekunda
Zgodnie z definicję jest to:
czas równy 9 192 631 770 okresom promieniowania odpowiadającego przejściu między dwoma poziomami F = 3 i F = 4 struktury nadsubtelnej stanu podstawowego S1/2 atomu cezu 133Cs (powyższa definicja odnosi się do atomu cezu w spoczynku w temperaturze 0 K)
Wow 🙂 Na całe szczęście ta definicja nie ma dla nas większego znaczenia i wystarczy znajomość relacji między poszczególnymi jednostkami.
Milisekunda
1 ms = 10−3 s = 1/1000 s
Mikrosekunda
1 μs = 10−6 s = 1/1 000 000 s
Nanosekunda
1 ns = 10−9 s = 1/1 000 000 000 s
Pikosekunda
1 ps = 10−12 s
W zależności od czasu, na jakim operujemy, nasze benchmarki możemy podzielić na Millibenchmarks, Microbenchmarks, Nanobenchmarks, Picobenchmarks itp.
Co to jest JMH – Java Microbenchmark Harness?
JMH to framework zaprojektowany w celu budowania i analizowania testów porównawczych (benchmarków) napisanych w Javie oraz innych językach maszyny wirtualnej.
W naszym konkretnym wypadku Java Microbenchmark Harness jest odpowiedzią na większość problemów związanych z mierzeniem wydajności naszego kodu. Dzięki tej stosunkowo niewielkiej bibliotece dostajemy pełne środowisko pozwalające pisać dużo lepsze testy porównawcze.
JMH jest otrzymywane przez ten sam zespół co JVM, a to zdecydowanie przemawia na jego korzyść.
Instalacja JMH
Jednym ze sposobów na instalację jest odpowiednie skonfigurowanie projektu Maven, wystarczy dodać te zależności.
org.openjdk.jmh jmh-core 1.21 org.openjdk.jmh jmh-generator-annprocess 1.21 provided
Najnowsze wersje jmh Core oraz JMH Annotation Processor można znaleźć w repozytorium Maven.
Alternatywnym podejściem jest wygenerowanie całego szablonu projektu, korzystając z Maven archetype.
>mvn archetype:generate \ -DinteractiveMode=false \ -DarchetypeGroupId=org.openjdk.jmh \ -DarchetypeArtifactId=jmh-java-benchmark-archetype \ -DgroupId=pl.stormit \ -DartifactId=benchmark \ -Dversion=1.0
Tak przygotowany projekt wystarczy zbudować oraz uruchomić wygenerowany plik jar.
mvn clean install java -jar target/benchmarks.jar
Powyższa komenda uruchomi wszystkie benchmarki znajdujące się w projekcie. Dodając do wywołania parametr -help, uzyskasz listę wszystkich parametrów konfiguracyjnych.
Pierwszy benchmark
Czas napisać samodzielnie swój pierwszy benchmark. Poniżej przykładowy kod:
public class FirstBenchmark {
@Benchmark
public void testMethod() {
// benchmark code
}
}
W najprostszej postaci wystarczy dodać tylko jedną adnotację @Benchmark, a resztą zajmie się już biblioteka. Bardzo podobnie jak w przypadku testów jednostkowych, np. jUnit.
Tak naprawdę już na tym etapie można z powodzeniem poprzestać i zostawić całą robotę domyślnej konfiguracji JMH, a uzyskane wyniki będą całkiem dobre. Jeżeli jednak masz bardziej specyficzne wymagania, zapraszam do dalszej lektury.
Poznajmy lepiej JMH!
Na jednej adnotacji @Benchmark biblioteka się nie kończy, przyjrzyjmy się teraz bliżej jej wszystkim możliwościom – jest ich naprawdę całkiem sporo.
Jak uruchomić nasz benchmark?
Możliwości na uruchomienie benchmarków jest co najmniej kilka. Wcześniej powiedzieliśmy sobie, jak uruchomić benchmarki z linii komend w zbudowanym projekcie. Ja jednak w trybie developerskim najczęściej korzystam z dodatkowej metody main, która uruchamia silnik JMH.
public static void main(String[] args) throws Exception {
org.openjdk.jmh.Main.main(args);
}
Powyższy kod przeszuka nasz projekt pod kątem metod oznaczonych jako benchmarki i je uruchomi. Także jeżeli w projekcie masz więcej benchmarków, to wszystkie zostaną uruchomione. Przeprowadzenie pełnych testów na domyślnej konfiguracji nawet dla naszej pustej przykładowej metody zajmie sporo czasu. Dzieje się tak, ponieważ framework wykonuje wiele iteracji testów w celu uśrednienia wyników oraz kilka iteracji próbnych, żeby rozgrzać Javę – więcej powiemy o tym już za chwilę.
Kolejnym sposobem na uruchomienie benchmarków jest skorzystanie z dostarczonych klas: OptionsBuilder oraz Runner.
public static void main(String[] args) throws Exception {
Options options = new OptionsBuilder()
.include(FirstBenchmark.class.getSimpleName())
.forks(1)
.build();
new Runner(options).run();
}
Mamy wtedy większą swobodę w sterowaniu tym, co dokładnie chcemy uruchomić.
Tryby przeprowadzania benchmarku
JMH daje możliwość przeprowadzenia testów w różnych trybach. Możemy dzięki temu określić, co chcemy mierzyć.
- Throughput – przepustowość – ilość operacji w jednostce czasu (domyślnie sekunda), czyli ile razy nasz kod da radę wykonać się w ciągu sekundy.
- Average Time – średni czas ze wszystkich prób, jaki był potrzebny na wykonanie kodu.
- Sample Time – bardziej statystyczne podejście do mierzenia czasu wykonania, wraz z podziałem na histogram oraz percentyle.
- Single Shot Time – mierzy, ile czasu zajmie wykonanie benchmarku za pierwszym razem – bez Java warm-up.
- All – wszystkie powyższe tryby razem.
Wyboru interesującego nas trybu dokonujemy przez dodatkową adnotację @BenchmarkMode na testowanej metodzie.
@Benchmark
@BenchmarkMode(Mode.AverageTime)
public void testMethod() {}
Jednostki czasowe
JMH daje nam możliwość określenia, w jakiej jednostce czasu chcemy zaprezentować wyniki: nanosekundy, sekundy itp.
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MINUTES)
public void testMethod() {}
Korzystając z klasy TimeUnit, do dyspozycji mamy takie możliwości:
- NANOSECONDS
- MICROSECONDS
- MILLISECONDS
- SECONDS
- MINUTES
- HOURS
- DAYS
Rozgrzewka – Warm-UP
Wszystkie pomiary zaczynamy od rozgrzewki, która jest domyślnie uruchamiana. Jednak na jej przebieg możemy wpłynąć przy pomocy adnotacji @Warmup. Poniższy kod wykona jedną iterację rozgrzewki, trwającą jedną sekundę.
@Benchmark
@Warmup(time = 1, timeUnit = TimeUnit.SECONDS, iterations = 1)
public void testMethod(){}
Właściwe pomiary – Measurement
W podobny sposób jak rozgrzewka przeprowadzane są właściwe pomiary. Tym razem, jeżeli chcemy zmodyfikować domyślne zachowanie, trzeba posłużyć się adnotacją @Measurement.
@Benchmark
@Measurement(time = 1, timeUnit = TimeUnit.SECONDS, iterations = 1)
public void testMethod() throws InterruptedException {}
Zarządzanie stanem benchmarku – State, Setup, TearDown
Czasem zachodzi potrzeba wydzielenia części parametrów poza główną logikę naszego benchmarku. Przykładowo, jeżeli chcesz przetestować, jak zachowa się Twój kod dla różnych danych wejściowych. Zamiast generować kilka bardzo podobnych testów, można niejako wstrzyknąć różne kombinacje danych wejściowych do benchmarku.
@State(Scope.Benchmark)
public class ParameterizedBenchmark {
@Param({"1", "2", "3"})
int param;
@Benchmark
public void testMethod() {
// benchmark code
}
}
Powyższy benchmark wykona się trzy razy, przy czym za każdym razem z inną wartością zmiennej param.
Klasa ParameterizedBenchmark została oznaczona adnotacją @State(Scope.Benchmark), dzięki czemu JMH wie, na jakim poziomie powinna wykorzystać stan tych parametrów.
Do dyspozycji mamy trzy stany:
- Thread – każdy wątek utworzy swoją własną instancję parametrów.
- Group – każda grupa wątków wykonująca test będzie miała własną instancję (o grupach powiemy sobie jeszcze za chwilę).
- Benchmark – wszystkie wątki wykorzystają tę samą instancję parametrów.
Ma to szczególnie duże znaczenie, gdy przejdziemy do kolejnego przykładu, gdzie zamiast typów prostych do naszego benchmarku przekażemy cały obiekt.
@State(Scope.Thread)
public static class Params {
public int x = 1;
public int y = 2;
public int sum;
}
@Benchmark
public void testMethod(Params params) {
params.sum = params.x + params.y;
}
W powyższym przykładzie doszedł nowy parametr metody z obiektem nowo utworzonej klasy Params. Klasa jest dodatkowo oznaczona adnotacją @State(Scope.Thread), co znaczy, że wszystkie wątki biorące udział w benchmarku dostaną swój własny obiekt.
Chcąc korzystać w ten sposób z obiektów klasy jako parametrów benchmarku, należy pamiętać, jakie warunki musi spełnić ta klasa:
- klasa musi być oznaczona jako publiczna;
- jeżeli klasa jest zagnieżdżona (jak w naszym przypadku), to musi być statyczna public static class...;
- klasa musi posiadać publiczny konstruktor bez argumentów.
@Setup, @TearDown
Korzystanie z klasy stanu ma jeszcze jedną ważną zaletę. Mamy możliwość zarządzania jej cyklem życia przez specjalne metody z adnotacjami @Setup oraz @TearDown.
@State(Scope.Thread)
public static class Params {
public int x = 1;
public int y = 2;
public int sum;
@Setup
public void setup() {
sum = 0;
System.out.println("run setup");
}
@TearDown
public void tearDown() {
System.out.println("run tearDown");
}
}
Daje to praktycznie nieograniczone możliwości zarządzania stanem parametrów. Metoda setup jest wywoływana przed przekazaniem obiektu do benchmarku, a metoda tearDown – po jego wykonaniu.
Istnieje również możliwość dodania kilku różnych metod z tymi adnotacjami.
Obie adnotacje dodatkowo przyjmują opcjonalny argument określający, kiedy dokładnie te metody mają zostać wywołane.
- Level.Trial – jest to domyślne zachowanie. Metoda jest wywoływana raz na całe wywołanie benchmarku – czyli raz na wszystkie iteracje testowe oraz rozgrzewające.
- Level.Iteration – metoda będzie wywołana raz dla każdej iteracji benchmarku.
- Level.Invocation – metoda będzie wywołana raz dla każdego całego wywołania testu.
Rozgałęzienia @Fork
Domyślnie JMH uruchamia każdy trial (czyli zbiór iteracji rozgrzewających i mierzących) jako osobny fork. Dzieje się tak, by poszczególne pomiary były możliwie niezależne i jak najmniej na siebie wpływały. Zazwyczaj nie powinniśmy tego zmieniać, jeżeli jednak zajdzie taka potrzeba, do dyspozycji mamy adnotację @Fork.
@Fork(value = 2)
@Benchmark
public void testMethod() {}
Przy jej pomocy można zmienić ilość forków dla triali, warm-up oraz dodatkowo podać dodatkowe argumenty do wywołania JVM.
Wątki @Threads
Biblioteka JMH ma bardzo fajne wsparcie dla wielowątkowości. Zacznijmy od prostego przykładu, w którym chcemy, by nasz kod wykonał się na kilku wątkach jednocześnie.
@Benchmark
@Threads(3)
public void testMethod() {
System.out.print(Thread.currentThread().getId()+", ");
}
Dzięki adnotacji @Threads określamy ilość wątków. Natomiast w ciele samego benchmarku wyświetlamy tylko id aktualnego wątku.
Grupy wątków @GroupThreads @Group
Ciekawiej zaczyna się robić, gdy zaczniemy pracować z grupami wątków. Spróbujmy zamodelować sobie przypadek, w którym mamy jedno źródło danych oraz kilka wątków, które odczytują te dane.
@State(Scope.Group)
public static class Params {
public int x = 1;
public int y = 2;
}
@Benchmark
@GroupThreads(2)
@Group("g1")
public void testMethod1(Params params) {
System.out.print(Thread.currentThread().getId() + ", ");
}
@Benchmark
@GroupThreads(3)
@Group("g1")
public void testMethod2(Params params) {
System.out.print(Thread.currentThread().getId() + ", ");
}
W pierwszym kroku adnotacją @State(Scope.Group) określamy nasze źródło danych, tak by było dostępne dla grupy. Następnie kolejną adnotacją @Group("g1") grupujemy nasze benchmarki. Na koniec możemy jeszcze dokonfigurować ilość wątków dla każdego benchmarku dzięki @GroupThreads. Dla całej grupy zostanie wykorzystana ilość wątków wynikająca z sumy wątków poszczególnych benchmarków, czyli w naszym przypadku 2 + 3 = 5.
Poszczególne testy z grupy zostaną uruchomione równolegle w tym samym trialu. Natomiast wyniki benchmarku zostaną podane dla każdej metody niezależnie oraz zbiorczo dla całej grupy.
Benchmark Mode Cnt Score Error Units ThreadsExample.g1 thrpt 6 33597.249 ± 26049.498 ops/s ThreadsExample.g1:testMethod1 thrpt 6 8574.895 ± 20059.811 ops/s ThreadsExample.g1:testMethod2 thrpt 6 25022.354 ± 41169.972 ops/s
Podpowiedzi dla kompilatora (compiler hints)
Biblioteka JMH daje nam również możliwość wpływu na zachowanie kompilatora przy pomocy adnotacji @CompilerControl.
@Benchmark
public void testMethod() {
method();
}
@CompilerControl(CompilerControl.Mode.INLINE)
private void method() {}
Do dyspozycji mamy kilka różnych trybów: BREAK, PRINT, EXCLUDE, INLINE, DONT_INLINE, COMPILE_ONLY.
W tym miejscu warto również zainteresować się argumentami maszyny wirtualnej Javy, takimi jak -XX:+PrintCompilation i -verbose:gc, żeby lepiej zrozumieć, co dzieje się pod spodem.
Jak pisać dobre benchmarki i na jakie pułapki uważać?
JMH nie rozwiąże za nas wszystkich problemów, da nam jednak odpowiednie narzędzia, które znacząco ułatwią proces projektowania dobrych benchmarków.
Warm-up, czyli zacznijmy od rozgrzewki
Domyślnie wszystkie benchmarki w JVM poprzedzane są fazą warm-up, także nie musisz tego robić ręcznie. Jeżeli jednak chcesz zmienić jej ustawienia, możesz skorzystać z adnotacji @Warmup.
@Benchmark
@Warmup(iterations = 5, timeUnit = TimeUnit.MILLISECONDS, time = 100)
public void testMethod(){}
Powyższy kod wykona 5 iteracji rozgrzewających, każda po 100 milisekund.
Eliminacja martwego kodu (dead code elimination)
Poniższy przykład z dużym prawdopodobieństwem zwróci nam zakłamane wyniki, ponieważ kompilator wykryje, że wynik tej operacji nigdzie nie jest wykorzystywany i zwyczajnie ominie ten kod!
@Benchmark
public void deadCode(){
int a = 1;
int b = 2;
int sum = a + b;
}
Mamy dwie możliwości, żeby uchronić się przed taką optymalizacją. Wystarczy:
- Zwrócić ostateczny wynik naszej operacji z metody testującej return sum.
- Przekazać wyniki operacji do czarnej dziury. JMH udostępnia specjalną klasę Blackhole, która może „konsumować” wyniki operacji, co zapobiegnie nadmiernej optymalizacji.
@Benchmark
public void blackHoleConsume(Blackhole blackhole){
int a = 1;
int b = 2;
int sum = a + b;
blackhole.consume(sum);
}
Żeby potwierdzić tę tezę, przeprowadziłem trzy testy dokładnie tego samego dodawania. Z tym że w dwóch przypadkach zastosowałem mechanizmy przeciwdziałające eliminacji martwego kodu. Spójrzcie na wyniki:
- deadCode – standardowe dodawanie;
- returnValue – wynik dodawania został zwrócony z metody testującej;
- blackHoleConsume – wykorzystałem wbudowany mechanizm czarnej dziury.
Benchmark Mode Cnt Score Error Units DeadCode.blackHoleConsume thrpt 5 435606566.030 ± 17237726.727 ops/s DeadCode.deadCode thrpt 5 3652411182.146 ± 88932266.478 ops/s DeadCode.returnValue thrpt 5 434312877.247 ± 20589656.127 ops/s
Wynik z pominięciem optymalizacji jest ponad 8 razy wolniejszy!
Wyliczanie wartości stałych (constant folding)
Wyliczanie wartości stałych to kolejna optymalizacja, na którą trzeba uważać. Zobaczmy to na poniższym przykładzie. Ponownie przygotowałem trzy przypadki testowe:
- constantFolding – standardowe dodawanie, które może zostać zoptymalizowane przez jego jednokrotne wyliczenie i podmianę wartości;
- constantFolded – w wyniku mechanizmu constant folding pierwszy przykład może zostać automatycznie przekształcony na taką postać. Lub nawet do samego return 0.0; , a w skrajnym wypadku kompilator może zrezygnować z wywołania metody i każde jej wywołanie zamienić na stałą;
- avoidConstantFolding – chcąc uchronić się przed tym mechanizmem, możemy wstrzyknąć parametry do naszej metody testującej.
@State(Scope.Thread)
public class ConstantFoldingBenchmark {
private int n = 21;
@Benchmark
public double avoidConstantFolding() {
return Math.log(n);
}
@Benchmark
public double constantFolding() {
return Math.log(21);
}
@Benchmark
public double constantFolded() {
return 1.32221929473;
}
}
Wyniki benchmarku potwierdzają nasze założenia.
ConstantFoldingBenchmark.avoidConstantFolding thrpt 5 38799034.262 ± 1180484.839 ops/s ConstantFoldingBenchmark.constantFolded thrpt 5 407250142.991 ± 23172182.143 ops/s ConstantFoldingBenchmark.constantFolding thrpt 5 406962930.002 ± 34492195.977 ops/s
Optymalizacja pętli
Kompilator świetnie radzi sobie z optymalizacją pętli, zobaczmy to na przykładzie.
@Param({"10", "10000", "10000000"})
private int n;
@Benchmark
public int loop() {
int sum = 0;
for (int i = 0; i < n; i++) {
sum++;
}
return sum;
}
Mimo znaczącej różnicy w ilości iteracji pętli łączny czas na wykonanie całej pętli jest praktycznie taki sam. Żeby uchronić się przed tego typu optymalizacjami, najlepiej zrezygnować z wykorzystania pętli w benchmarku i testom poddać tylko logikę z ciała pętli.
Benchmark (n) Mode Cnt Score Error Units LoopBenchmark.loop 10 thrpt 5 365791813.120 ± 28541569.462 ops/s LoopBenchmark.loop 10000 thrpt 5 374484447.982 ± 13230154.673 ops/s LoopBenchmark.loop 10000000 thrpt 5 363040228.406 ± 38938864.195 ops/s
Zadanie do samodzielnego wykonania i materiały uzupełniające
Czas zweryfikować wiedzę w praktyce. Zachęcam do przeprowadzenia samodzielnych testów, np. konkatenacji stringów w Javie, sprawdzenia, jak wypadnie standardowe dodawanie ciągów znaków w porównaniu do StringBuffer itp.
Rozwiązanie tego zadania oraz wszystkie przykłady z tego tekstu są do podejrzenia na GitHub. Swoim rozwiązaniem oraz ewentualnymi wątpliwościami zawsze możesz podzielić się na grupie.
- https://github.com/StormITpl/JavaExamples/tree/master/benchmark
- https://stormit.pl/stringbuilder/
- http://hg.openjdk.java.net/code-tools/jmh/file/tip/jmh-samples/src/main/java/org/openjdk/jmh/samples/
- https://shipilev.net/talks/devoxx-Nov2013-benchmarking.pdf
- http://openjdk.java.net/projects/code-tools/jmh/
Benchmark podsumowanie – jak mierzyć wydajność kodu w Javie?
Jak widzicie, znaleźliśmy całkiem sporo potencjalnych problemów, na które można natrafić podczas mierzenia czasu wykonania kodu, a tak naprawdę jest to dopiero wierzchołek góry lodowej. Chcąc sobie z tym poradzić, musimy wprowadzić pewne założenia oraz ograniczenia. Pisanie dobrych benchmarków z pewnością nie jest trywialnym zadaniem, jednak, posiłkując się odpowiednimi narzędziami, np. Java Microbenchmark Harness, możemy sobie ten proces usprawnić i osiągnąć całkiem dobre wyniki przy stosunkowo niewielkim wysiłku. Trzeba tylko pamiętać, że żadne, nawet najlepsze narzędzie nie załatwi za nas całej roboty i to od nas zależy, czy odpowiednio je wykorzystamy.
Ze swojej strony dziękuję Ci za dotrwanie aż do tego miejsca i życzę powodzenia w optymalizacji swoich aplikacji.
