

W tym wpisie pokażę Ci, jak twórcy Javy zaimplementowali takie struktury danych, jak FIFO i LIFO oraz zdradzę, jak możesz zrobić to samodzielnie.
Następnie przekonam Cię, że wcale nie warto tego robić ręcznie i lepiej skorzystać z ich pracy.
Zapraszam do lektury.
Z tej serii dowiesz się:
- co to jest LIFO, FIFO, HIFO, FEFO, FINO oraz FISH; 🙂
- co to jest i jak działa stos (ang. stack);
- jak działa kolejka (ang. queue) oraz kolejka priorytetowa (ang. priority queue);
- jak samodzielnie zaimplementować takie struktury danych;
- oraz jak korzystać z gotowych rozwiązań.
Stos (ang. Stack)
Programiści bardzo chętnie czerpią z doświadczeń życia codziennego – podobnie jest i w tym wypadku.
Zastanów się – z czym kojarzy Ci się pojęcie stos?
Może to być: stos książek, stos talerzy do zmywania, stos drewna do palenia itp.
Jest to zwyczajnie kilka rzeczy ułożonych jedna na drugiej. Dokładnie tak samo jest w informatyce – stos danych rozumiemy jako zbiór elementów „ułożonych jeden na drugim”.
Jak w takim razie dostać się do poszczególnych elementów w takim stosie?
Wyobraź sobie, że leży przed tobą stos książek ułożonych jedna na drugiej.
Spróbuj teraz wziąć książkę, która znajduje się na samym szczycie tego stosu – będzie to dość łatwe. Prawda?
Teraz zróbmy coś trudniejszego.
Postaraj się wziąć książkę, która jest w środku tego stosu lub na jego samym spodzie.
Co musisz zrobić?
Zakładamy, że nie chcesz mieć porozrzucanych książek po całym pokoju, dlatego najrozsądniej byłoby zdejmować od góry kolejne książki i odkładać je na bok tak długo, aż znajdziesz swoją wybraną książkę.
Taki typ kolejkowaniu elementów nazywamy: LIFO.
LIFO (ang. Last In, First Out)
Wszystkie elementy w stosie ułożone są zgodnie z zasadą LIFO.
LIFO (ang. Last In, First Out) – w dosłownym tłumaczeniu oznacza: ostatnie przyszło, pierwsze wyszło.
Metoda LIFO w kontekście obsługi magazynów nazywana jest również metodą najpóźniejszej dostawy – jako pierwsze zostaną wydane elementy/produkty, które najkrócej były przechowywane.
Wracając do naszego przykładu ze stosem książek.
Żeby wyjąć książkę, która jest na samym dole stosu, musisz zdjąć z niego kolejno wszystkie książki – poczynając od tych na samej górze.
Przez takie ułożenie danych w stosie:
- łatwo jest zdjąć z niego elementy z samego wierzchu;
- jeżeli natomiast chcemy pobrać elementy znajdujące się niżej, to musimy przejść przez wszystkie te, które są nad nim.
LIFO vs FIFO
Przeciwieństwem do omawianego tu stosu i organizacji elementów zgodnie z LIFO
jest kolejka z elementami ułożonymi wg zasady FIFO (ang. First In, First Out) – czyli pierwszy na wejściu, pierwszy na wyjściu.
Więcej na ten temat będziesz mógł przeczytać w drugiej części tego wpisu:
Kolejka (Queue) – jak samodzielnie zaimplementować FIFO?
LIFO i stos w informatyce
Bufory w formie stosu LIFO bardzo chętnie wykorzystywane są w informatyce do przechowywania danych lub jako system planowania zadań.
Omówimy sobie teraz główne koncepcje związane z wykorzystywaniem stosu.
Głowa (ang. head)
Zacznijmy od pojęcia głowy (ang. head) stosu – jest to wskaźnik określający, w którym miejscu znajduje się najnowszy/pierwszy element stosu.
Poszczególne operacje, które możemy na nim wykonać, takie jak dodanie elementu do stosu (ang. push), podejrzenie pierwszego elementu (ang. peek), czy jego pobranie (ang. pop), zawsze operują właśnie na tym wskaźniku.
Stos push (ang. stack push)
Metoda stos push (ang. stack push) polega na dodaniu nowego elementu – „kładziemy” nowy element na wierzchu stosu i od teraz wskaźnik head wskazuje właśnie na ten element.
")
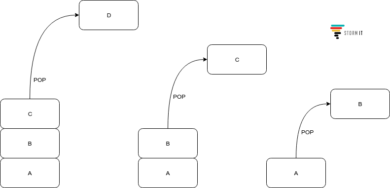
Stos pop (ang. stack pop)
Metoda stos pop (ang. stack pop) zwraca pierwszy element ze stosu, jednocześnie go zdejmując – czyli bierzemy jedną rzecz z samej góry stosu i ją zabieramy. Przez co, po wykonaniu tej metody, wskaźnik head wskazuje na element, który był niżej w stosie lub – jeżeli nie mamy już elementów – to head = null.
Stos peek (ang. stack peek)
Metoda stos peek (ang. stack peek) działa podobnie jak stos pop, zwracając pierwsze element ze stosu, jednak nie modyfikuje zawartości samego stosu. Można ją wykorzystać np. do podejrzenia, jaki element jest na wierzchu naszej struktury danych.
Stos w Javie (ang. Stack Java)
Przyjrzyjmy się teraz bliżej, co Java oferuje nam w kontekście tych struktur danych.
Zamieszczone poniżej fragmenty kodu napisane są w Javie, jednak przykłady są na tyle uniwersalne, że nie powinno być problemu z odniesieniem ich do innych języków programowania.
W Javie mamy do dyspozycji kilka klas implementujących stos i LIFO.
Zaczniemy od java.util.Stack, który jest klasyczną strukturą danych dziedziczącą po java.util.Vector, a co za tym idzie – implementującą między innymi java.util.List.
Przy jej pomocy możemy wykonać wszystkie podstawowe operacje: push, pop i peek.
1. Utworzenie stosu
Stack stack = new Stack();
lub wersja ze wsparciem dla typów generycznych:
Stackstack = new Stack ();
2. Dodawanie nowego elementu (ang. stack push)
stack.push("1");
3. Zdjęcie ze stosu pierwszego elementu (ang. stack pop)
String pop = stack.pop();
4. Pobranie pierwszego elementu bez modyfikacji stosu (ang. stack peek)
String peek = stack.peek();
5. Przeszukiwanie stosu (ang. stack search)
Stackstack = new Stack (); stack.push("1"); stack.push("2"); stack.push("3"); stack.push("4"); // when int search1 = stack.search("2"); // 3 int search2 = stack.search("0"); // -1
Metoda search zwraca pozycję danego elementu na stosie lub -1, jeżeli nie znajdzie takiego elementu.
UWAGA: Pozycje numerowane są od 1, czyli obiekt, który znajduje się na samej górze stosu, ma numer 1, kolejny 2 i tak dalej.
6. Przeszukiwanie stosu – indeks elementu
Do przeszukiwania stosu możemy również wykorzystać metodę: public int indexOf(Object o) .
UWAGA: W tym wypadku jednak elementy będą numerowane od 0 i zaczynamy liczyć od elementu, który jest na samym dole stosu 🙂
int indexOf1 = stack.indexOf("2"); // 1
int idnexOf2 = stack.indexOf("0"); // -1
7. Przeglądanie stosu (ang. stack iterate)
Elementy na stosie możemy przeglądać na kilka różnych sposobów, np. korzystając ze wbudowanego iteratora: stack.iterator().
W tej sytuacji należy jednak pamiętać, że elementy będą zwracane w kolejności od tego na samym spodzie stosu!
Stackstack = new Stack (); stack.push("A"); stack.push("B"); stack.push("C"); Iterator it = stack.iterator(); while (it.hasNext()) { String item = it.next(); System.out.println(item); }
Alternatywnie można skorzystać z pętli while oraz metody pop – jak w drugim przykładzie.
while (!stack.isEmpty()) {
String item = stack.pop();
System.out.println(item);
}
8. Korzystanie ze stosu przy pomocy strumieni i wyrażeń lambda (ang. stack java stream)
Nic nie stoi na przeszkodzie, żeby ze stosu korzystać przy pomocy strumieni i wyrażeń lambda.
Najpierw pobieramy strumień, korzystając z metody: stream(), i wykonujemy niezbędne operacje.
Poniżej kilka przykładów.
- Wyświetlenie wszystkich elementów na standardowe wyjście.
Stackstack = new Stack<>(); stack.push(1); stack.push(2); stack.push(3); stack.push(4); stack.stream().forEach(System.out::print); System.out.println();
- Zamiana stosu na listę.
Listlist = stack.stream().collect(Collectors.toList()); System.out.println(list);
- Usunięcie wybranych elementów.
stack.removeIf(element -> element > 3);
- Zamiana stosu na tablicę.
int[] intArray = stack.stream() .mapToInt(element -> element) .toArray(); System.out.println(Arrays.toString(intArray));
Rekomendowana implementacja stosu w Javie (java.util.Deque)
Na java.util.Stack świat Javy się nie kończy. Do dyspozycji mamy jeszcze chociażby interfejs: java.util.Deque oraz dwie implementacje: java.util.ArrayDeque i java.util.LinkedList.
Mimo iż jest to inny interfejs i inne implementacje, to zasada działania powyższych klas z punktu widzenia użytkownika jest analogiczna.
Możemy skorzystać ze standardowych metod: push, pop i peek oraz w przypadku np. LinkedList wielu innych.
Warto jest się przyjrzeć temu rozwiązaniu nie tylko dlatego, że daje ono więcej możliwości, ale jest to również implementacja rekomendowana przez twórców samej Javy.
Jako główny argument przeciwko java.util.Stack podawany jest fakt, że nie mamy rozdzielonego interfejsu i implementacji, a sama klasa dziedziczy po przestarzałym już java.util.Vector.
Poniżej kilka przykładów z wykorzystaniem Deque.
// given Dequedeque = new LinkedList<>(); deque.push(1); deque.push(2); deque.push(3); // when Integer pop = deque.pop(); Integer peek = deque.peek(); int size = deque.size(); // then assertThat(pop).isEqualTo(3); assertThat(peek).isEqualTo(2); assertThat(size).isEqualTo(2);
Przepełnienie stosu
Poznaliśmy już podstawy, dlatego pobawmy się teraz z odrobinę ciekawszymi zagadnieniami.
A co gdyby tak dodawać do naszego stosu w nieskończoność nowe elementy? 🙂
Wracając do naszego pierwotnego przykładu z książkami – na brak książek w domu nie mogę narzekać, także raczej by mi ich szybko nie zabrakło.
Podejrzewam jednak, że powyżej pewnej wysokości wszystko by całkiem nieźle walnęło... (Znasz taką grę Jenga? Jeżeli nigdy w nią nie grałeś, to gorąco polecam.)
W informatyce taki pomysł musi skończyć się podobnie – coś na pewno się zepsuje lub skończy.
Zasadniczo mamy dwa możliwe scenariusze:
- skończy nam się pamięć i cała aplikacja się wysypie;
- lub implementacja stosu uzna, że nie może już przyjmować nowych obiektów i nam to zakomunikuje. Jeżeli odpowiednio przechwycimy taki komunikat, to jest szansa, że uratujemy jeszcze aplikację. Jeżeli nie, to i w tym wypadku całka aplikacja się złoży.
Dequestack = new LinkedList<>(); long i = 0; while (true) { stack.push(i++); }
OutOfMemoryError
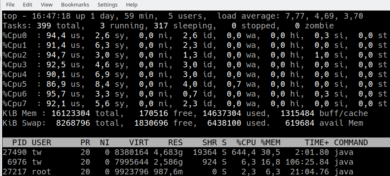
Po wykonaniu powyższego kodu mój komputer na chwilę przygasł...
Java wykorzystała ponad 600% CPU, po czym cały proces zakończył swój żywot, zgłaszając błąd: java.lang.OutOfMemoryError: Java heap space.
Wniosek z tego przykładu płynie taki, że nie możemy bezkarnie w nieskończoność dodawać elementów do stosu ani żadnej innej struktury danych.
Jeżeli chcemy się ustrzec przed podobnymi problemami, trzeba przemyśleć strategię usuwania starych elementów lub w pewnym momencie powiedzieć STOP i przestać dodawać kolejne elementy.
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at java.base/java.lang.Long.valueOf(Long.java:1180) at pl.stormit.stacklifo.DequeTest.x(DequeTest.java:37) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.base/java.lang.reflect.Method.invoke(Method.java:566)
Jednak nie tylko my jako szeregowi programiści musimy uważać na tego typu problemy.
Z analogicznymi trudnościami musieli zmierzyć się również programiści samej Javy.
StackOverflowError
Przyjrzymy się teraz bliżej niechlubnemu błędowi: java.lang.StackOverflowError.
Możemy się z nim spotkać, gdy np. napiszemy nieskończoną rekurencję – fragment kodu, który w nieskończoność będzie wywoływał sam siebie.
Kod poniżej z założenia będzie wywoływał w nieskończoność tę samą metodę – chyba że...
@Test
void invinityStack2() {
invinityStack2();
}
Chyba że skończy nam się miejsce na stosie 🙂
Każde wywołanie metody w Javie odkładane jest na wewnętrznym stosie, a po zakończeniu wykonywania takiej metody zdejmowane z tego stosu.
No chyba że wpadniemy na pomysł, żeby w nieskończoność wywoływać jakąś metodę i cały czas dodawać nowe wpisy do tego stosu.
Wtedy musimy się liczyć, że dostaniemy taki wyjątek:
java.lang.StackOverflowError at pl.stormit.stacklifo.DequeTest.invinityStack2(DequeTest.java:43) at pl.stormit.stacklifo.DequeTest.invinityStack2(DequeTest.java:43) at pl.stormit.stacklifo.DequeTest.invinityStack2(DequeTest.java:43) at pl.stormit.stacklifo.DequeTest.invinityStack2(DequeTest.java:43) at pl.stormit.stacklifo.DequeTest.invinityStack2(DequeTest.java:43) at pl.stormit.stacklifo.DequeTest.invinityStack2(DequeTest.java:43) at pl.stormit.stacklifo.DequeTest.invinityStack2(DequeTest.java:43) at pl.stormit.stacklifo.DequeTest.invinityStack2(DequeTest.java:43)
Stos w innych językach programowania (PHP, Python, C++)
PHP
W PHP stos możemy zaimplementować z wykorzystaniem np. metod: array_unshift i array_shift lub oprzeć się na gotowych rozwiązaniach.
stack = array();
// stack can only contain this many items
\$this->limit = \$limit;
}
public function push(\$item) {
// trap for stack overflow
if (count(\$this->stack) < \$this->limit) {
// prepend item to the start of the array
array_unshift(\$this->stack, \$item);
} else {
throw new RunTimeException('Stack is full!');
}
}
public function pop() {
if (\$this->isEmpty()) {
// trap for stack underflow
throw new RunTimeException('Stack is empty!');
} else {
// pop item from the start of the array
return array_shift(\$this->stack);
}
}
public function top() {
return current(\$this->stack);
}
public function isEmpty() {
return empty(\$this->stack);
}
}
Źródło: Data Structures for PHP Devs: Stacks and Queues
Python
W minimalistycznej wersji w Pythonie możemy skorzystać ze zwykłej listy jako stosu.
>>> stack = []
>>> stack.append('A')
>>> stack.append('B')
>>> stack.append('C')
>>> stack.pop()
'C'
>>> stack.pop()
'B'
>>> stack.pop()
'A'
>>> stack.pop()
Traceback (most recent call last):
File "", line 1, in
IndexError: pop from empty list
Po więcej szczegółów odsyłam do zewnętrznego artykułu: How to Implement a Python Stack.
C/C++
Przykładowa implementacja stosu w C++.
#include#include using namespace std; void showstack(stack s) { while (!s.empty()) { cout << '\t' << s.top(); s.pop(); } cout << '\n'; } int main () { stack s; s.push(10); s.push(30); s.push(20); s.push(5); s.push(1); cout << "The stack is : "; showstack(s); cout << "\ns.size() : " << s.size(); cout << "\ns.top() : " << s.top(); cout << "\ns.pop() : "; s.pop(); showstack(s); return 0; }
Źródło: Stack in C++ STL.
Inny systemy kolejkowania
Do pełnego obrazu sytuacji brakuje nam już tylko wyjaśnienia innych skrótowców, które często pojawiają się w kontekście FIFO.
FCFS (ang. First-Come, First-Served)
FCFS (ang. First-Come, First-Served) – czyli w dosłownym tłumaczeniu: pierwsze przyjdzie, pierwsze będzie podane. Skrótowiec wykorzystywany najczęściej w kontekście zarządzania zapasami.
FEFO (ang. First Expired, First Out)
FEFO (ang. First Expired, First Out) – czyli w dosłownym tłumaczeniu pierwsze, które będzie przedawnione, pierwsze idzie na zewnątrz. Tego typu podejście może być np. wykorzystane przy łatwo psujących się produktach lub takich o krótkim terminie przydatności.
Z punktu widzenia technicznego jest to po prostu kolejka priorytetowa (ang. priority queue).
FINO (ang. First In, Never Out)
FINO (ang. First In, Never Out) – to dowód na to, że programiści też mają poczucie humoru 🙂
FINO możemy przetłumaczyć na: pierwsze weszło, nigdy nie wyszło – co oczywiście ma być prześmiewczą analogią do FIFO i LIFO.
FISH (ang. First In, Still Here)
FISH (ang. First In, Still Here) – akronim FISH powstał na podobnej zasadzie jak FINO, tłumaczymy go jako: pierwsze weszło, ciągle tam jest.
Samodzielna implementacja LIFO (Stack)
Na koniec pobawimy się jeszcze praktycznymi zadaniami.
Powiedzieliśmy sobie, że elementy w stosie ułożone są zgodnie z zasadą LIFO. Jednak sam stos może być zaimplementowany na kilka różnych sposobów.
Najczęściej możemy spotkać się z dwiema implementacjami stosu:
- opartej o cykliczny bufor danych (ang. circular buffer) lub
- zaimplementowanej z wykorzystaniem listy – najczęściej listy wskaźnikowej (ang. linked list),
- choć możliwa jest też implementacja z wykorzystaniem zwykłej tablicy.
Przerobienie tych przykładów nie jest konieczne do zrozumienia omawianych tu pojęć i w zdecydowanej większości przypadków dużo lepszym wyjściem jest skorzystanie z gotowych już klas implementujących stos, takich jak java.util.LinkedList.
Mimo wszystko zachęcam do ich przejrzenia i samodzielnej próby implementacji – jest to świetny sposób na utrwalenie wiedzy w praktyce i pełniejsze zrozumienie tematu.
W poniższych przykładach skupię się na ręcznej implementacji z wykorzystaniem własnej listy wskaźnikowej (ang. linked list).
Interfejs stosu i główne wymagania
Nasz stos powinien implementować wszystkie podstawowe metody, takie jak: pop, push, peek i size. Zanim jednak przejdziemy do samej implementacji, zacznijmy od zdefiniowania interfejsu – czyli określmy, co właściwie będzie robił nasz stos.
Na tym etapie jeszcze nie określamy, jak będzie to realizowane – tym zajmiemy się podczas implementacji.
public interface Stack{ T peek(); T pop(); void push(T value); int size(); }
Wewnętrzna struktura przechowująca elementy
Każdy element na naszym stosie będzie się składał z samej wartości przechowywanego elementu oraz informacji o tym, jaki element znajduje się pod nim. Dzięki temu, mając referencję do najwyższego elementu, będziemy mogli dostać się do pozostałych.
private static class Entry{ private T value; private Entry ; public Entry(T value, Entry prev) { this.value = value; this.prev = prev; } }
Wskaźnik na głowę (ang. head) stosu
Potrzebujemy jeszcze przechować informację o tym, który element jest na samej górze – robimy to przy pomocy wskaźnika: head.
public class LinkedStackimplements Stack { private Entry head; }
Rozmiar stosu (ang. stack size)
Żeby za każdym razem nie liczyć wszystkich elementów, które są na stosie, do przechowania rozmiaru wykorzystamy wewnętrzną zmienną.
private int size = 0;
Dodanie elementu do stosu (ang. push)
Dodając nowy element do stosu:
- tworzymy wewnętrzną strukturę, która przechowuje nasz element oraz informację o poprzednim elemencie, który był na szczycie stosu, czyli dotychczasowej głowie;
- podmieniamy wskaźnik przechowujący głowę stosu na nasz nowy obiekt;
- i na końcu inkrementujemy zmienną przechowującą rozmiar stosu.
@Override
public void push(T value) {
Entry entry = new Entry(value, head);
head = entry;
size++;
}
Zdjęcie elementu ze stosu
Chcąc zdjąć element ze stosu:
- sprawdzamy, czy stos nie jest pusty (head == null);
- pobieramy wartość elementu wskazywanego przez head;
- nadpisujemy wskaźnik head, tak by wskazywał na element znajdujący się pod nim;
- zwracamy wartość elementu.
public T pop() {
if (head == null) {
return null;
}
T value = head.value;
head = head.prev;
size--;
return value;
}
Podejrzenie elementu znajdującego się na szczycie stosu
Metoda peek sprawdza, czy stos nie jest pusty i zwraca wartość obiektu wskazywanego przez head.
public T peek() {
if (head == null) {
return null;
}
return head.value;
}
Pełna implementacja
interface Stack{ T peek(); T pop(); void push(T value); int size(); } class LinkedStack implements Stack { private static class Entry { private T value; private Entry prev; public Entry(T value, Entry prev) { this.value = value; this.prev = prev; } } private Entry head; private int size = 0; @Override public T peek() { if (head == null) { return null; } return head.value; } @Override public T pop() { if (head == null) { return null; } T value = head.value; head = head.prev; size--; return value; } @Override public void push(T value) { Entry entry = new Entry (value, head); head = entry; size++; } @Override public int size() { return size; } }
Zadania do samodzielnego rozwiązania
Jeżeli ciągle szukasz wyzwań i chcesz poćwiczyć zadania z wykorzystaniem stosu – poniżej masz kilka inspiracji.
- odwrócenie listy elementów przy pomocy stosu;
- samodzielna implementacja stosu przy pomocy wewnętrznej tablicy.
Rozwiązania wszystkich zadań i inne przykłady kodu znajdziesz na repozytorium github.
Podsumowanie i druga część wpisu
Na dzisiaj to już wszystko. Bardzo Ci dziękuję, że wytrwałeś do końca. Zachęcam Cię przede wszystkim do samodzielnego wypróbowania omawianego dziś stosu oraz rozwiązania zadań. Wynikami swojej pracy możesz jak zawsze podzielić się na grupie.
A już niedługo druga część wpisu: Kolejka (Queue) – jak samodzielnie zaimplementować FIFO?
Dodatkowe materiały:
- kurs java
- Java tablice | Kurs Java
- Struktury danych – podstawy algorytmów
- Jak się uczyć programowania? Sprawdzone sposoby na naukę nowych rzeczy i pogłębianie wiedzy.
